
1. Quick Start#
Molass Library is designed to achieve the following motto:
Easy things should be easy, and hard things should be possible.
which is a quote from Larry Wall, the creator of the Perl language. Although Perl gave way to Python and we will use Python, this motto is ubiquitous in software library design.
Here in this chapter, we will show the easy part to give an idea of what it is all about. If the input data are well conditioned, this will suffice to get what you will expect in ordinary use. However, life is not so easy and that is why the hard part exists, which we will discuss in the later chapters.
1.1. Installation#
We assume you have already installed Python and you are familiar with Jupyter Notebook.
To install the Molass Library package, you can use pip as follows:
pip install -U molass
pip install -U molass_data
Note
The molass_data package includes some data sets for this tutorial.
1.2. Tools for Jupyter Notebooks#
For programming in Jupyter Notebooks, we recommend either of the following tools (other alternatives are also possible):
We recommend using Jupyter notebooks mainly for the following reason:
Interactive Exploration with Visualization
Notebooks let you write and run code in small, manageable cells. You can experiment with different parameters, immediately see the results, and iteratively refine your analysis—most importantly, all of this without restarting your workflow from scratch. This makes it easy to test ideas, debug, and learn by doing.
1.3. Straightforward Usage#
1.3.1. Plot the Input Data#
We can plot the data set as follows. The format of this data set is specified in the chapter 4 of MOLASS User’s Guide.
from molass import get_version
assert get_version() >= '0.6.1', "This tutorial requires molass version 0.6.1 or higher."
from molass_data import SAMPLE1
from molass.DataObjects import SecSaxsData as SSD
ssd = SSD(SAMPLE1)
ssd.plot_3d(title="3D Plot of Sample1");
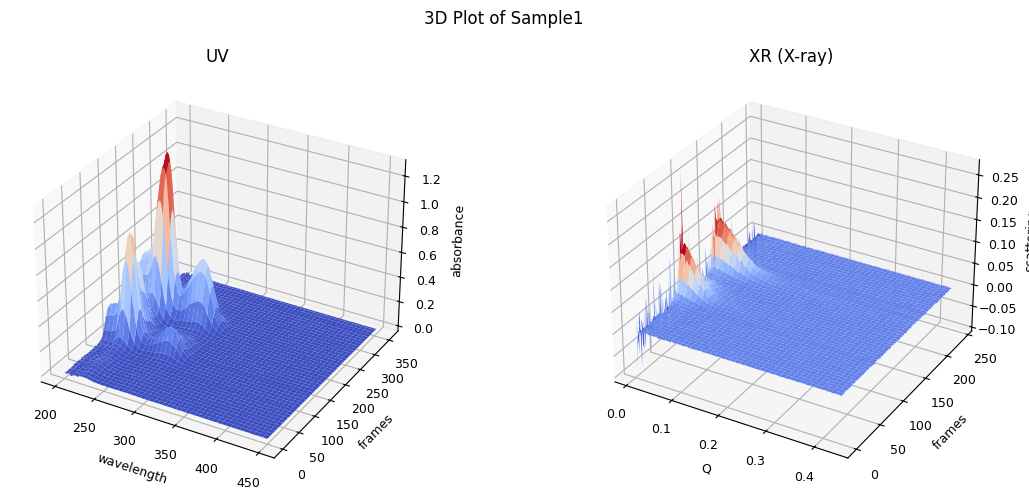
1.3.2. Trimming, Correction and LRF#
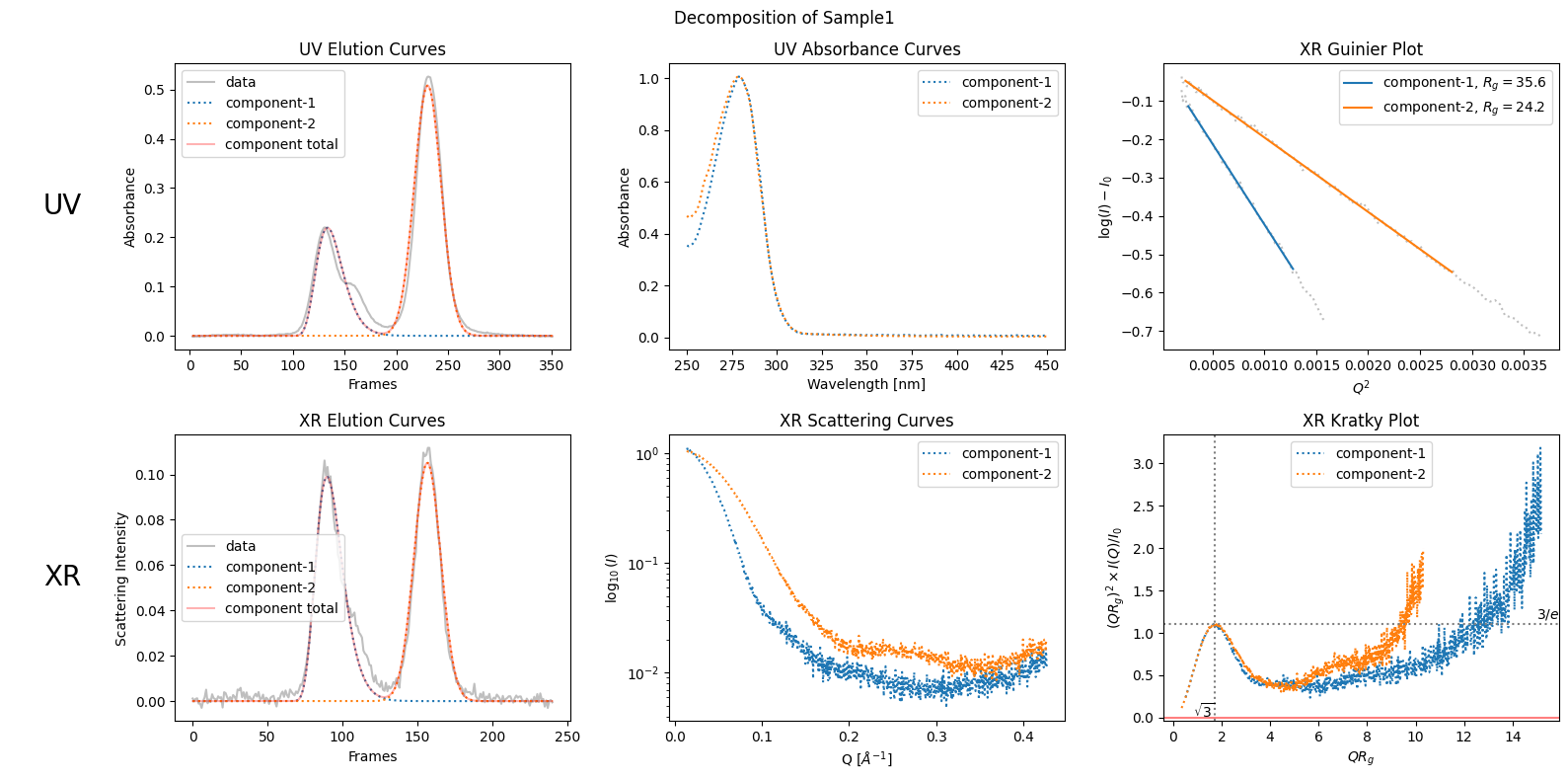
For simplicity, we assume here that the data set contains two components because we observe two chromatographic peaks, ignoring the bump observed on the right side of the first peak. To obtain a set of well-estimated scattering curves for each component, we usually need to apply three steps: trimming, baseline correction, and LRF (low rank factorization). We can execute these steps and show the results as follows. The details of each step will be explained in later chapters.
trimmed_ssd = ssd.trimmed_copy()
corrected_ssd = trimmed_ssd.corrected_copy()
decomposition = corrected_ssd.quick_decomposition()
decomposition.plot_components(title="Decomposition of Sample1");
zeros at the angular ends of error data have been replaced with the adjacent values.
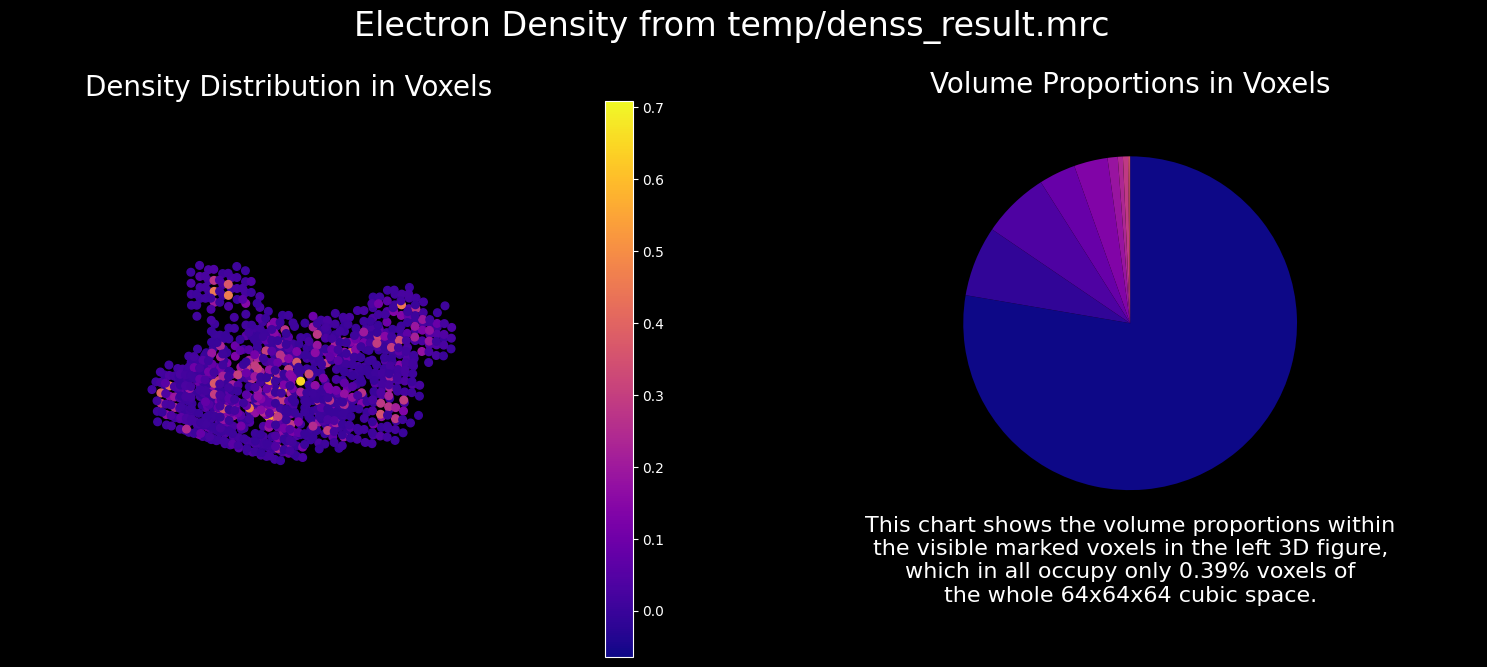
1.3.3. Running DENSS#
From the result of LRF, which is expressed as “decomposition” here in the python code, we can obtain the scattering curve of each component. Once you have a well-conditioned scattering curve, you can reconstruct the original electron density distribution using an appropriate SAXS tool. In Molass Library, you can use DENSS directly as follows.
from molass.SAXS.DenssTools import run_denss
# Get, for example, the first component's scattering curve as an array
jcurve_array = decomposition.get_xr_components()[0].get_jcurve_array()
output_folder = "temp"
run_denss(jcurve_array, output_folder=output_folder)
WARNING: Only 2 columns given. Data should have 3 columns: q, I, errors.
WARNING: Setting error bars to 1.0 (i.e., ignoring error bars)
Step Chi2 Rg Support Volume
----- --------- ------- --------------
620 2.59e-02 62.96 1011014
switched to shrinkwrap by density threshold = 0.2000
999 2.83e-05 35.96 346830 EC: 1 -> 1
2342 1.01e-05 36.12 307343
1.3.4. Plotting the DENSS Result#
The DENSS result can be visualized as follows.
import matplotlib.pyplot as plt
from molass.SAXS.MrcViewer import show_mrc
# Uncomment the following magic command line if you want to use an interactive plot in Jupyter Notebook
# %matplotlib widget
show_mrc(output_folder + '/denss_result.mrc');
1.4. How to Refine#
There are several aspects that can be improved, such as:
Data Selection (Trimming)
Baseline Correction
Decomposition of Overlapping Peaks
Interparticle Interactions (Concentration Dependence)
In the straightforward usage shown above, the parameters on these factors are determined roughly in favor of simplicity and speed.
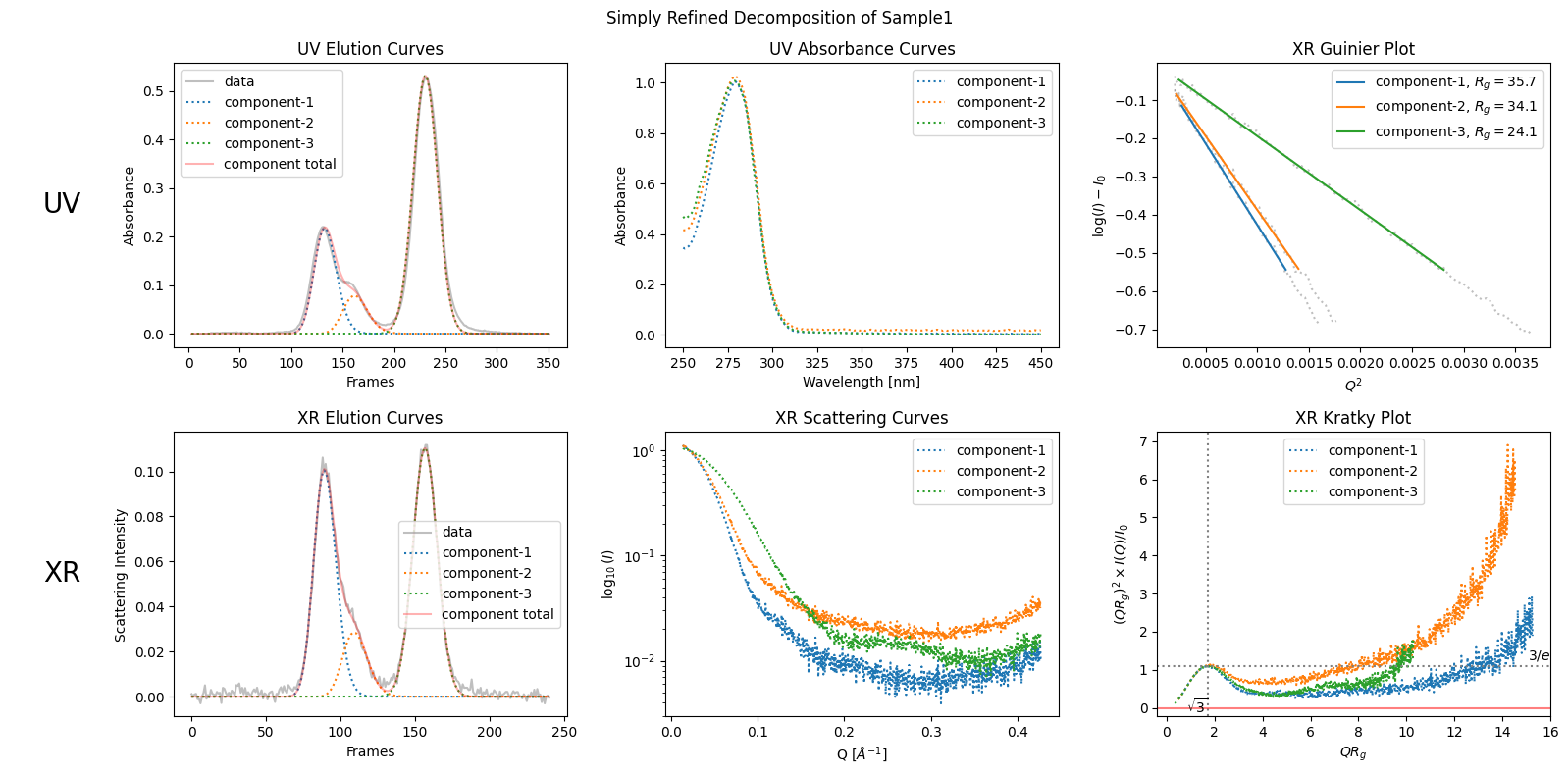
However, if you want to be more precise and decide that the observed bump should be considered as a sign of a separate component, you can specify the number of components as follows.
simply_refined_decomposition = corrected_ssd.quick_decomposition(num_components=3)
simply_refined_decomposition.plot_components(title="Simply Refined Decomposition of Sample1");
Molass Library provides several other options and methods for better estimation of scattering curves which we will discuss one by one in later chapters.
1.5. How to Export#
As we have passed the decomposed data to DENSS above, jcurve_array is the commonly used portable style which consists of the three column vectors, namely, [qvector, intensities, errors]. Do as follows, for example, to export the all decomposed scattering curves.
import numpy as np
for i, comp in enumerate(simply_refined_decomposition.get_xr_components()):
jcurve_array = comp.get_jcurve_array()
np.savetxt(f"component_{i+1}.dat", jcurve_array)
1.6. How to Customize#
If you want to try this straightforward usage for your data, you will probably need to cumstomize for your data. In such cases, see the Customization chapter in the Molass Technical Report.